A Constructive Look at Follow Through Results
Carl Bereiter, Ontario Institute for Studies in Education, and
Midian Kurland, University of Illinois at Urbana-Champaign
Reprinted from Interchange, Vol. 12, Winter, 1981,
with permission.
Follow Through is a large compensatory education program that operated
in scores of communities across the United States throughout the seventies and
that continues, on a reduced scale, today. During its most active phase, it
was conducted as a massive experiment, involving planned variation of
education approaches and collection of uniform data at each site. The main
evaluation of outcomes was carried out by Abt Associates, Inc. (a private
consulting firm, based in Cambridge, Massachusetts) on the second and third
cohorts of children who reached third grade in the program, having entered in
kindergarten or first grade. In a series of voluminous reports, Abt Associates
presented analyses indicating that among the various education approaches
tried, only those emphasizing "basic skills" showed positive effects when
compared to Non-Follow Through treatments. House, Glass, McLean, and Walker
(1978a) published a critique of the Abt Associates evaluation, along with a
small reanalysis that found essentially no significant differences in
effectiveness among the planned variations in educational approaches. Because
of the great social importance attached to educational programs for
disadvantaged groups and because no other large-scale research on the topic is
likely to materialize in the near future, the Follow Through experiment
deserves continuing study. The study reported here is an attempt, through more
sharply focused data analysis, to obtain a more definitive answer to the
question of whether different educational approaches led to different
achievement outcomes.
Is it possible that the Follow Through planned variation experiment has
yielded no findings of value? Is it possible, after years of effort and millions
of dollars spent on testing different approaches, that we know nothing more than
we did before about ways to educate disadvantaged children? This is the implicit
conclusion of the widely publicized critique by House, Glass, McLean, and Walker
(1978a, 1978b). House et al found no evidence that the various Follow Through
models differed in effectiveness from one another or from Non-Follow Through
programs. The only empirical finding House et al were willing to credit was that
there was great variation in results from one Follow Through site to another.
This conclusion, as we shall show, is no more supportable than the conclusions
House et al rejected. Accordingly, if we were to follow House, Glass, McLean,
and Walker's lead, we should have to conclude that there are no substantive
findings to be gleaned from the largest educational experiment ever
conducted.
It would be a serious mistake, however, to take the critique
by House et al as any kind of authoritative statement about what is to be
learned from Follow Through. The committee assembled by House was charged with
reviewing the Abt Associates evaluation of Follow Through (Stebbins et al,
1977), not with carrying out an inquiry of their own. More or less, the
committee stayed within the limits of this charge, criticizing a variety of
aspects of the design, execution, and data analysis of the experiment. Nowhere
in their report do the committee take up the constructive problem that Abt
Associates had to face or that any serious inquiries will have to face. Given
the weaknesses of the Follow Through experiment, how can one go about trying to
extract worthwhile findings from it?
In this paper we try to deal
constructively with one aspect of the Follow Through experiment: the comparison
of achievement test results among the various sponsored approaches. We try to
show that if this comparison is undertaken with due cognizance of the
limitations of the Follow Through experiment, it is possible to derive some
strong, warranted, and informative conclusions. We do not present our research
as a definitive, and certainly not as a complete, inquiry into Follow Through
results. We do hope to show, however, that the conclusion implied by the House
committee-that the Follow Through experiment is too flawed to yield any positive
findings-is gravely mistaken.
Delimiting the Problem
Although Project Follow Through has numerous shortcomings as an experiment,
the seriousness of these shortcomings varies greatly depending on what questions
are asked of the data. One shortcoming was in the outcome measures used,
particularly in their limited range compared to the range of objectives pursued
by Follow Through sponsors. The House committee devotes the largest part of its
critique to this shortcoming, although it is a shortcoming that limits only the
range of conclusions that may be drawn. House et al allow, for instance, that
the Metropolitan Achievement Test was "certainly a reasonable choice for the
material it covers" (1978a, p. 138). Accordingly, Follow Through's shortcomings
as to outcome measures ought not to stand in the way of answering questions that
are put in terms appropriate to the measures that were used.
Another
shortcoming, recognized by all commentators on Follow Through, is the lack of
strictly comparable control groups. Follow Through and Non-Follow Through groups
at the same site differed from one another in uncontrolled and only partly
measurable ways, and the differences themselves varied from site to site. This
circumstance makes it difficult to handle questions having to do with whether
children benefited from being in Follow Through, because such questions require
using Non-Follow Through data as a basis for inferring how Follow Through
children would have turned out had they not been in Follow Through.
Much
of the bewildering complexity of the Abt Associates' analyses results from
attempts to make up statistically for the lack of experimental comparability. We
do not intend to examine those attempts except to note one curiosity. The
difficulty of evaluating "benefits" holds whether one is asking about the
effects of Follow Through as a whole, the effects of a particular model, or the
effect of a Follow Through program at a single site. The smaller the unit,
however, the more vulnerable the results are likely to be to a mismatch between
Follow Through and Non-Follow Through groups. On the one hand, to the extent
that mismatches are random, they should tend to average out in larger
aggregates. On the other hand, at a particular site, the apparent success or
failure of a Follow Through program could depend entirely on a fortuitously
favorable or unfavorable match with a Non-Follow Through group.
For
unknown reasons, both the Abt Associates and the House committee analysts have
assumed the contrary of the point just made. While acknowledging, for instance,
that the prevalence of achievement test differences in favor of Non-Follow
Through groups could reflect mismatch, they are able to make with confidence
statements like "Seven of the ten Direct Instruction sites did better than the
comparison classes but three of the Direct Instruction sites did worse" (House
et al, 1978a, p. 154). Such a statement is nonsense unless one believes that at
each of the ten sites a valid comparison between Follow Through and Non-Follow
Through groups could be made. But if House et al believe that, how could they
then believe that the average of those ten comparisons is invalid? This is like
arguing that IQ tests give an invalid estimate of the mean intelligence level of
disadvantaged children and then turning around and using those very tests to
classify individual disadvantaged children as retarded.
There is an
important class of questions that may be investigated, however, without having
to confront the problem of comparability between Follow Through and Non-Follow
Through groups. These are questions involving the comparison of Follow Through
models with one another. A representative question of this kind would be-how did
the Follow Through models compare with one another in reading achievement test
scores at the end of third grade? There are problems in answering such a
question, but the lack of appropriate control groups is not one of them. We can,
if we choose, simply ignore the Non-Follow Through groups in dealing with
questions of this sort.
Questions about the relative performance of
different Follow Through models are far from trivial. The only positive
conclusions drawn by Abt Associates relate to questions of this kind, and the
House committee's report is largely devoted to disputing those conclusions -that
is, disputing Abt's conclusions that Follow Through models emphasizing basic
skills achieved better results than others in basic skills and in self-concept.
The models represented in Follow Through cover a wide range of educational
philosophies and approaches to education. Choose any dimension along which
educational theories differ and one is likely to find Follow Through models in
the neighborhood of each extreme. This is not to say that the Follow Through
models are so well distinguished that they provide clean tests of theoretical
issues in education. But the differences that are there-like, for instance, the
difference between an approach based on behavior modification principles and an
approach modeled on the English infant school-offer at least the possibility of
finding evidence relevant to major ideological disputes within education.
Unscrambling the Methodology
The Abt Associates analysts were under obligation to try to answer the whole
range of questions that could be asked about Follow Through effects. In order to
do this in a coherent way, they used one kind of statistic that could be put to
a variety of uses. This is the measure they called "effect size," an adjusted
mean difference between the Follow Through and Non-Follow Through subjects at a
site. Without getting into the details of how effect size was computed, we may
observe that this measure is more suitable for some purposes than for others.
For answering question about benefits attributable to Follow Through, some such
measure as effect size is necessary. For comparing one Follow Through model with
another, however, the effect size statistic has the significant disadvantage
that unremoved error due to mismatch between a Follow Through and Non-Follow
Through group is welded into the measure itself. As we noted in the preceding
section, comparisons of the effectiveness of Follow Through models with one
another do not need to involve Non-Follow Through data. Because effect size
measures will necessarily include some error due to mismatch (assuming that
covariance adjustments cannot possibly remove all such error), these measures
will contain "noise" that can be avoided when making comparisons among Follow
Through models.
The Abt Associates analysts used several different ways
of computing effect size, the simplest of which is called the "local" analysis.
This method amounts to using the results for each cohort of subjects at each
site as a separate experiment, carrying out a covariance analysis of Follow
Through and Non-Follow Through differences as if no other sites or cohorts
existed. Although this analysis has a certain elegance, it clearly does not take
full advantage of the information available; the "pooled" analysis used by Abt,
which uses data on whole cohorts to calculate regression coefficients and at the
same time includes dummy variables to take care of site-specific effects, is
much superior in this respect. The House committee, however, chose to use effect
size measures based on the "local" analysis in their own comparison of models.
In doing so, they used the least powerful of the Abt effect size measures, all
of which are weakened (to unknown degrees) by error due to mismatch.
In
their comparisons of Follow Through models, Abt Associates analysts calculated
the significance of effects at different sites, using individual subjects at the
sites as the units of analysis, and then used the distribution of significant
positive and negative effects as an indicator of the effectiveness of the
models. The House committee argued, on good grounds we believe, that the
appropriate unit of analysis should have been sites rather than individual
children. To take only the most obvious argument on this issue, the manner of
implementing a Follow Through model is a variable of great presumptive
significance, and it is most reasonably viewed as varying from site to site
rather than from child to child. Having made this wise decision, however, the
House committee embarked on what must be judged either an ill-considered or an
excessively casual reanalysis of Follow Through data. Although the reanalysis of
data by the House committee occupies only a small part of their report and is
presented by them with some modesty, we believe their reanalysis warrants severe
critical scrutiny. Without that reanalysis, the House committee's report would
have amounted to nothing more than a call for caution in interpreting the
findings of the Abt Associates analysts. With the reanalysis, the House
committee seems to be declaring that there are no acceptable findings to be
interpreted. Thus a great deal hinges on the credibility of their
reanalysis.
Let us therefore consider carefully what the House committee
did in their reanalysis. First, they used site means rather than individual
scores as the unit of analysis. This decision automatically reduced the Follow
Through planned variation experiment from a very large one, with an N of
thousands, to a rather small one, with an N in the neighborhood of one hundred.
As previously indicated, we endorse this decision. However, it seems to us that
when one has opted to convert a large experiment into a small one, it is
important to make certain adjustments in strategy. This the House committee
failed to do. If an experiment is very large, one can afford to be cavalier
about problems of power, since the large N will presumably make it possible to
detect true effects against considerable background noise. In a small
experiment, one must be watchful and try to control as much random error as
possible in order to avoid masking a true effect.
However, instead of
trying to perform the most powerful analysis possible in the circumstances, the
House committee weakened their analysis in a number of ways that seem to have no
warrant. First, they chose to compare Follow Through models on the basis of
Follow Through/Non-Follow Through differences, thus unnecessarily adding error
variance associated with the Non-Follow Through groups. Next, they chose to use
adjusted differences based on the "local" analysis, thus maximizing error due to
mismatch. Next, they based their analysis on only a part of the available data.
They excluded data from the second kindergarten-entering cohort, one of the
largest cohorts, even though these data formed part of the basis for the
conclusions they were criticizing. This puzzling exclusion reduced the number of
sites considered, thus reducing the likelihood of finding significant
differences. Finally, they divided each effect-size score by the standard
deviation of test scores in the particular cohort in which the effect was
observed. This manipulation served no apparent purpose. And minor though its
effects may be, such as they are would be in the direction of adding further
error variance to the analysis.
The upshot of all these methodological
choices was that, while the House group's reanalysis largely confirmed the
ranking of models arrived at by Abt Associates, it showed the differences to be
small and insignificant. Given the House committee's methodology, this result is
not surprising. The procedures they adopted were not biased in the sense of
favoring one Follow Through model over another; hence it was to be expected that
their analysis, using the same effect measures as Abt, would replicate the
rankings obtained by Abt. (The rank differences shown in Table 7 of the House
report are probably mostly the result of the House committee's exclusion of data
from one of the cohorts on which the Abt rankings were based.) On the other
hand, the procedures adopted by the House committee all tended in the direction
of maximizing random error, thus tending to make differences appear small and
insignificant.
The analysis to be reported here is of the same general
type as that carried out by the House committee. Like the House committee, we
use site means rather than scores for individuals as the unit of analysis. The
differences in procedure all arise from our effort to minimize random error and
thus achieve the most powerful analysis possible. The following are the main
differences between our analysis and the House et al analysis:
1. We used site means for Follow Through groups as the dependent variable,
using other site-level scores as covariates. The House committee used locally
adjusted site-level differences between Follow Through and Non-Follow Through
groups as the dependent variable, with covariance adjustments having been made
on an individual basis. Our procedure appears to have been endorsed in advance
by the House committee. They state: "For the sake of both inferential validity
and proper covariance adjustment, the classroom is the appropriate unit of
analysis" (House et al, 1978a, p. 153). While the House committee followed
their own prescription in using site-level scores as dependent variables, they
failed to follow it when it came to covariance adjustments.
2. When we
used Non-Follow Through scores, we entered them as covariates along with other
covariates. The procedure adopted by the House committee amounted, in effect,
to arbitrarily assigning Non-Follow Through mean scores a regression weight of
1 while giving all other variables empirically determined regression weights.
We could not see any rational basis for such a deviation from ordinary
procedures for statistical adjustment.
3. We combined all data from one
site as a single observation, regardless of cohort. The House committee appear
to have treated different cohorts from the same site as if they were different
sites. This seemed to us to violate the rationale for analyzing data at the
site level in the first place.
4. We restricted the analysis to models
having data on 6 or more sites. To include in the analysis models having as
few as 2 sites, as the House committee did, would, it seemed to us, reduce the
power of the statistical tests to an absurd level.
The data analysis that followed from the above-mentioned decisions was
quite straightforward and conventional. The dependent variable was always the
mean score for a site on one or more Metropolitan Achievement Test subtests,
averaged over all subjects in cohorts II and III for whom data were reported in
the Abt Associates reports. Models, which ranged from 12 to 6 in number of
sites, were compared by analysis of covariance, using some or all of the
following covariates:
SES-An index of socio-economic status calculated by
Abt for each cohort at each site. When more than one cohort represented a site,
an n-weighted mean was computed.
EL-An index of ethnic and linguistic
difference from the mainstream-treated in a manner similar to
SES.
WRAT-Wide-range Achievement Test, administered near time of entry to
Follow Through students. Taken as a general measure of academic
readiness.
NFT-Mean score of local Non-Follow Through students on the
dependent variable under analysis. As a covariate, NFT scores may be expected to
control for unmeasured local or regional characteristics affecting scholastic
achievement.
Two other covariates were tried to a limited extent: Raven
Progressive Matrices scores (which, though obtained after rather than before
treatment, might be regarded as primarily reflecting individual differences
variance not affected by treatment) and a score indicating the number of years
of Follow Through treatment experienced by subjects at a site (most Follow
Through groups entered in kindergarten, thus receiving four years of Follow
Through treatment; but some entered in first grade and received only three
years). Our overall strategy for use of analysis of covariance was as follows:
recognizing that reasonable cases could be made for and against the use of this
covariate or that, we would try various combinations and, in the end, would take
seriously only those results that held up over a variety of reasonable covariate
sets.
Results
Differences in achievement test performance-Two analyses of covariance will
be reported here, with others briefly summarized. Figure 1 displays adjusted and
standardized means from what we call the "full" analysis of covariance-that is,
an analysis using the four main covariates (SES, EL, WRAT, and NFT) described in
the preceding section. The virtue of this analysis is that it controls for all
the main variables that previous investigators have tried, in one way or other,
to control for in comparing Follow Through models.
Table 1* notes
pair-wise differences which are significant at the .05 level by Newman-Keuls
tests.
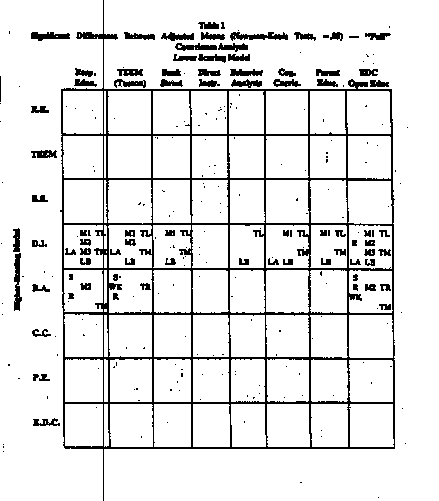
Figure 2* and Table 2* show comparable
data for what we call the "conservative" analysis.
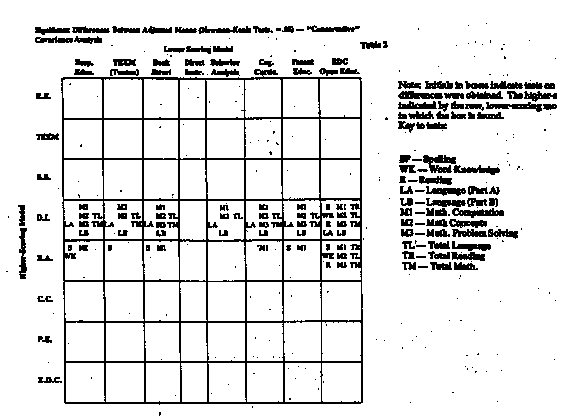
This analysis is conservative in the sense that it
eliminates covariates for which there are substantial empirical and/or rational
grounds for objection. Grounds for objecting to the NFT variable as a covariate
have been amply documented in Abt reports and echoed in the report of the House
committee (House et al, 1978a); they will not be repeated here. Use of WRAT as a
covariate has been objected to on grounds that it is not, as logically required,
antecedent to treatment (Becker & Carnine, Ref. Note 1)-that is, the WRAT,
though nominally a pretest, was in fact administered at a time when at least one
of the models had already purportedly taught a significant amount of the content
touched on by the WRAT. While we would not suppose the SES and EL variables to
be above reproach, we have not encountered criticisms suggesting their use would
seriously bias results-whereas not to control for these variables would
unquestionably leave the results biased in favor of models serving less
disadvantaged populations. Accordingly, we have chosen them as the conservative
set of covariates.
Other analyses, not reported, used different
combinations of covariates from among those mentioned in the preceding section.
In every case, these analyses yielded adjusted scores intermediate between those
obtained from the "full" and the "conservative" analyses. Consequently, the
results shown in Figures 1 and 2 may be taken to cover the full range of those
observed.
In every analysis, differences between models were significant
at or beyond the .05 level on every achievement variable-almost all beyond the
.01 level. As Figures 1 and 2 show, models tended to perform about the same on
every achievement variable. Thus there is little basis for suggesting that one
model is better at one thing, another at another.
The relative standing
of certain models, particularly the Tucson Early Education Model, fluctuated
considerably depending on the choice of covariates.1 Two models, however, were
at or near the top on every achievement variable, regardless of the covariates
used; these were Direct Instruction and Behavior Analysis. Two models were at or
near the bottom on every achievement variable, regardless of the covariates
used; these were the EDC Open Education Model and Responsive Education.
Differences between the two top models and the two bottom models were in most
cases statistically significant by Newman-Keuls tests.
Variability
between sites-The only empirical finding that the House committee was willing to
credit was that there was enormous variability of effects from site to site
within Follow Through models. In their words: "Particular models that worked
well in one town worked poorly in another. Unique features of the local settings
had more effect on achievement than did the models" (House et al, 197&, p.
156). This conclusion has recently been reiterated by the authors of the Abt
evaluation report (St. Pierre, Anderson, Proper, & Stebbins, 1978) in almost
the same words.
The ready acceptance of this conclusion strikes us as
most puzzling. It is conceivable that all of the variability between sites
within models is due to mismatch between Follow Through and Non-Follow Through
groups. This is unlikely, of course, but some of the variability between sites
must be due to this factor, and unless we know how much, it is risky to make
statements about the real variability of effects. Furthermore there is, as far
as we are aware, no evidence whatever linking achievement to "unique features of
the local setting." This seems to be pure conjecture-a plausible conjecture, no
doubt, but not something that should be paraded as an empirical
finding.
Our analyses provide some basis for looking at the between-site
variability question empirically. Follow Through sites varied considerably in
factors known to be related to achievement-socioeconomic status, ethnic
composition, WRAT pretest scores, etc. To say that the variance in achievement
due to these factors was greater than the variance due to model differences may
be true but not very informative. It amounts to nothing more than the
rediscovery of individual differences and is irrelevant to the question of how
much importance should be attached to variation among Follow Through models. To
say that differences in educational method are trivial because their effects are
small in comparison to the effect of demographic characteristics is as absurd as
saying that diet is irrelevant to children's weight because among children
weight variations due to diet are small in comparison to weight variations due
to age.
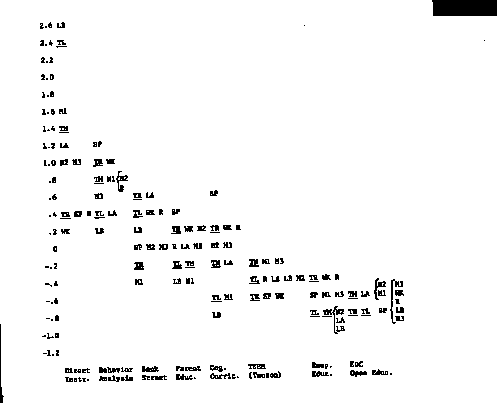
Figure 1*
Standardized adjusted mean Metropolitan Achievement Test scores obtained
from "full" covariance analysis (rounded to the nearest even
tenth).
The variability issue may be more cogently formulated as
follows: considering only the variance in achievement that cannot be accounted
for by demographic and other entering characteristics of students, what part of
that variance can be explained by differences in Follow Through models and what
part remains unexplained? Our analyses provide an approximate answer to this
question, since covariance adjustments act to remove variance among sites due to
entering characteristics. Depending on the achievement test variable considered
and on the covariates used, we found model differences to account for roughly
between 17 and 55 per cent of the variance not attributable to covariates (as
indexed by w2).
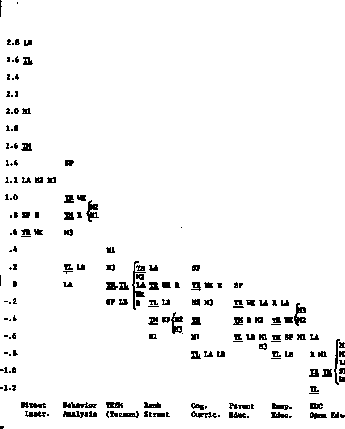
Figure 2*
Standardized adjusted mean Metropolitan Achievement Test scores obtained
from "conservative" covariance analysis (rounded to the nearest even
tenth).
These results are shown graphically in Figures 1 and 2.
Adjusted mean scores are displayed there in units of the standard deviation of
residual site means. Thus, to take the most extreme case, in Figure 2 the
adjusted mean score of Direct Instruction sites on Language Part B is 3.6
standard deviations above the adjusted mean score of EDC Open Education
sites-that is, 3.6 standard deviations of between-site residual variability; in
other words, an enormous difference compared to differences between sites within
models. That is the most extreme difference, but in no case is the adjusted
difference between highest and lowest model less than 1.4 standard deviations.
Although what constitutes a "large" effect must remain a matter of judgment, we
know of no precedent according to which treatment effects of this size could be
considered small in relation to the unexplained variance.
Treatment
effects on other variables-Although the principal concern of this study was with
achievement test differences, the method of analysis is adaptable to studying
differences in other outcomes as well. Accordingly we ran several briefer
analyses, looking at what Abt Associates call "cognitive / conceptual" and
"affective" outcomes.
Two kinds of measures used in the Follow Through
evaluation were regarded by Abt Associates as reflecting "cognitive /
conceptual" outcomes- Raven's Progressive Matrices (a nonverbal intelligence
test) and several Metropolitan subtests judged to measure indirect cognitive
consequences of learning. The House committee objected to Progressive Matrices
on grounds that is insensitive to school instruction. This rather begs the
question of effects of cognitively-oriented teaching, however. True, Progressive
Matrices performance may be insensitive to ordinary kinds of school instruction,
but does that mean it will be insensitive to novel instructional approaches
claiming to be based on cognitive theories and declaring such objectives as "the
ability to reason" and "logical thinking skills in four major cognitive areas
(classification, seriation, spatial relations and temporal relations)"? It seems
that this should be an empirical question.
If it is an empirical
question, the answer is negative. Using the same kinds of covariance analyses as
were used on the achievement test variables, we found no statistically
significant differences between Follow Through models in Progressive Matrices
performance. This finding is consistent with the Abt Associates' analyses, which
show few material effects on this test, and more negative than positive
ones.
Among Metropolitan subtests the most obviously "cognitive" are
Reading (which is, in effect, paragraph comprehension) and Mathematics
Problem-Solving. As indicated in Figures 1 and 2, our analyses show differences
among models on these subtests that are similar in trend to those found on the
other subtests. They tend, however, to be of lesser magnitude. The most obvious
explanation for the lesser magnitude of difference on these subtests is the same
as that offered by House et al for the absence of differences on Progressive
Matrices-that these subtests, reflecting more general differences in
intellectual ability, are less sensitive to instruction. There is, however, a
further hypothesis that should be tested. Conceivably, certain models-let us say
those that avowedly emphasize "cognitive" objectives-are doing a superior job of
teaching the more cognitive aspects of reading and mathematics, but the effects
are being obscured by the fact that performance on the appropriate subtests
depends on mechanical proficiency as well as on higher-level cognitive
capabilities. If so, these hidden effects might be revealed by using performance
on the more "mechanical" subtests as covariates.
This we did. Model
differences in Reading (comprehension) performance were examined, including Word
Knowledge as a covariate. Differences in Mathematics Problem Solving were
examined, including Mathematics Computation among the covariates. In both cases
the analyses of covariance revealed no significant differences among models.
This is not a surprising result, given the high correlation among Metropolitan
subtests. Taking out the variance due to one subtest leaves little variance in
another. Yet it was not a forgone conclusion that the results would be negative.
If the models that proclaimed cognitive objectives actually achieved those
objectives, it would be reasonable to expect those achievements to show up in
our analyses.
The same holds true for performance on the affective
measures included in the Follow Through evaluation. The Abt Associates' analyses
show that the ranking of models on affective measures corresponds closely to
their ranking on achievement measures. House et al point out, however, that the
instruments used place heavy demands on verbal skills. Conceivably, therefore,
if reading ability were controlled statistically, the results might tell a
different story. We analyzed scores on the Coopersmith Self-Concept Inventory,
including reading subtest scores along with the other covariates. The result
showed no significant difference among models on the Coopersmith. This finding
could mean either that there are no differences between models in effects on
self-concept or that self-concept among disadvantaged third-graders is
sufficiently dependent on reading ability that, when one statistically removes
reading ability differences, one at the same time removes genuine self-concept
differences. We know of no way to resolve this ambiguity with the available
data. One thing is clear, however: removing effects due to reading achievement
does not in any way yield results either favoring models that emphasize
self-concept or disfavoring models that emphasize academic objectives.
Discussion
Before attempting to give any interpretation of Follow Through results, we
must emphasize the main finding of our study-that there were results. Follow
Through models were found to differ significantly on every subtest of the
Metropolitan Achievement Test.
Let us briefly compare our findings with
those of Abt Associates and the House committee.
1. We disagree with both
Abt and House et al in that we do not find variability among sites to be so
great that it overshadows variability among models. It appears that a large part
of the variability observed by Abt and House et al was due to demographic
factors and experimental error. Once this variability is brought under control,
it becomes evident that differences between models are quite large in relation
to the unexplained variability within models.
2. Our findings on the
ranking of Follow Through models on achievement variables are roughly in accord
with those of the House Committee, but we differ from the House committee in
finding significant differences among models on all achievement variables
whereas they found almost none. The similarities are no doubt due to the fact
that the two analyses used the same basic units-site-level means. The difference
in significance of outcomes is apparently due to the variety of ways (previously
discussed) in which our analysis was more powerful than theirs.
3. The
Abt Associates' results indicate that among major Follow Through models, there
is only one "winner" in the sense of having a preponderance of positive
effects-namely, Direct Instruction. All other models showed predominately null
or negative effects. Our results are not exactly comparable in that we compared
Follow Through models only with one another and not with Non-Follow Through
groups; consequently we cannot speak of "positive" or "negative" effects.
However, our results show two models to be above average on all achievement
subtests and two models to be below average on all subtests. Thus our results
may be said to indicate two "winners"-Direct Instruction and Behavior Analysis-
and two "losers"-EDC Open Education and Responsive Education.
We put the
words "winners" and "losers" in quotation marks because, of course, Follow
Through was not a contest with the object of attaining the highest possible
achievement test scores. It simply happens that the outcomes on which Follow
Through models are found to differ are achievement test scores. That other
criteria might have shown different winners and losers (a point heavily
emphasized by the House committee) must remain a conjecture for which all the
available evidence is negative. What we have are achievement test differences,
and we must now turn to the question of what those differences might
mean.
It lies outside the scope of this paper to discuss the importance
of scholastic achievement itself. The more immediate issue is whether the
observed differences in achievement test scores reflect actual differences in
mastery of reading, mathematics, spelling, and language.
One obvious
limitation that must be put on the results is that the Metropolitan Achievement
Test, like all other standardized achievement batteries, covers less than the
full range of achievement objectives. As House et al point out, the test does
not cover "even such straightforward skills as the ability to read aloud, to
write a story, or to translate an ordinary problem into numbers" (1978b, p.
473). This much is certainly true, but House et al then go on to say, "it would
be reckless to suppose that the results of the testing indicate the attainment
of these broader goals" (p. 473). "Reckless" is far too strong a word here.2
From all we know about the intercorrelation of scholastic skills, one could be
fairly confident in assuming that children who perform above average on the MAT
would also perform above average on tests of the other skills mentioned. A
glance again at Figures 1 and 2 tells us that achievements in a variety of areas
tend to go together. Given the homogeneous drift of scores downward from left to
right in those figures, it is hard to imagine another set of achievement
measures in mathematical and language skills that would show a trend in the
opposite direction. Such a trend cannot be declared impossible, of course, but
if House et al expect us to take such a possibility seriously, then they ought
to provide some evidence to make it plausible.
A more serious kind of
charge is that the MAT is biased in favor of certain kinds of programs. If true,
this could mean that the observed test score differences between models reflect
test bias and not true differences on the achievement variables that the test is
supposed to measure. We must be very careful, however, in using the term bias.
One sometimes hears in discussions of Follow Through statements that the MAT is
biased in favor of models that teach the sort of content measured by the MAT.
This is a dangerous slip in usage of the word bias and must be avoided. It makes
no sense whatever to call it bias when an achievement test awards higher scores
to students who have studied the domain covered by the test than to students who
have not. It would be a very strange achievement test if it did not.
It
is meaningful, however, to say that an achievement test is biased in its
sampling of a domain of content, but even here one must be careful not to abuse
the term. The Mathematics Concept subtest of the MAT, for instance, is a
hodge-podge of knowledge items drawn from "old math," "new math," and who knows
what. For any given instructional program, it will likely be found that the test
calls for knowledge of material not covered by that program-but that doesn't
mean the test is biased against the program. The test obviously represents a
compromise that cannot be fully satisfactory to any program. The only ground for
a charge of bias would be that the compromise was not even-handed. Investigating
such a charge would require a thorough comparison of content coverage in the
test and content coverage in the various Follow Through programs. It does no
good to show that for a particular program there are discrepancies between
content covered and content tested. The same might be equally true of every
program.
As far as the Follow Through evaluation goes, the only MAT
subtest to which a charge of content bias might apply (we have no evidence that
it does) is Mathematics Concepts. The other subtests all deal with basic skills
in language and mathematics. Different programs might teach different methods of
reading or doing arithmetic, and they might give different amounts of emphasis
to these skills, but the skills tested on the MAT are all ones that are
appropriate to test regardless of the curriculum. Even if a particular Follow
Through model did not teach arithmetic computation at all, it would still be
relevant in an assessment of that program to test students' computational
abilities; other people care about computation, even if the Follow Through
sponsor does not. The reason why Mathematics Concepts may be an exception is
that, while everyone may care about mathematical concepts, different people care
about different ones, and so a numerical score on a hodge-podge of concepts may
not be informative.
While such skill tests as those making up the bulk of
the MAT are relatively immune to charges of content bias, they can be biased in
other ways. They may, perhaps, be biased in the level of cognitive functioning
that they tap within a skill area. The House committee implies such a bias when
they say, "the selection of measures favors models that emphasize rote learning
of the mechanics of reading, writing, and arithmetic" (House et al, 1978a, p.
14S). This is a serious charge and, if true, would go some way toward
discrediting the findings.
But House et al offer no support for this
charge, and on analysis it seems unlikely that they could. Their statement rests
on three assumptions for which we know of no support: (1) That "the mechanics of
reading, writing, and arithmetic" can be successfully taught by rote; (2) that
there were Follow Through models that emphasized rote learning (the model
descriptions provided by Abt give no suggestion that this is true)3 and (3) that
the MAT measures skills in such a way that the measurement favors children who
have learned those skills by rote rather than through a meaningful process. We
must conclude, in fact, that since the House committee could not have been so
naive as to hold all three of these assumptions, they must have introduced the
word "rote" for rhetorical effect only. Take the word out and their statement
reduces to an unimpressive complaint about the limited coverage of educational
objectives in the Follow Through evaluation.
A final way in which skill
tests might be biased is in the form of the test problems. Arithmetic
computation problems, for instance, might be presented in notation that was
commonly employed in some programs and not in others; or reading test items
might use formats similar to those used in the instructional materials of one
program and not another. Closely related to this is the issue of "teaching for
the test"-when this implies shaping the program to fit incidental features of a
test such as item formats. We may as well throw in here the issue of
test-wiseness itself as a program outcome-that is, the teaching of behaviors
which, whether intended to do so or not, help children perform well on
tests-since it bears on the overall problem of ways in which a program might
achieve superior test scores without any accompanying superiority in actual
learning of content. In short, children in some programs might simply get better
at taking tests.
If one looks at the Direct Instruction and Behavior
Analysis models, with their emphasis on detailed objectives and close monitoring
of student progress, and compares them to EDC Open Education, with its disavowal
of performance objectives and repudiation of standardized testing, it is
tempting to conclude in the absence of any evidence that the former models must
surely have turned out children better prepared to look good on tests,
regardless of the children's true states of competence. Without wishing to
prejudge the issue, we must emphasize that it is an empirical question to what
extent children schooled in the various Follow Through models were favored or
disfavored with respect to the process of testing itself.
In general,
children involved in the Follow Through evaluation were subjected to more
standardized testing than is normal. Since studies of test-wiseness indicate
rapidly diminishing returns from increasing amounts of familiarization with
testing (Cronbach, 1960), there is presumptive evidence against claims that
differential amounts of test-taking among models could be significant in
accounting for test-score differences. It should be possible to investigate this
matter with Follow Through data, though not from the published data. Children in
the final Follow Through evaluation had been subjected to from two to five
rounds of standardized testing. Accordingly it should be possible to evaluate
the effect of frequency of previous testing on third-grade test
scores.
There are, however, numerous ways in which Follow Through
experience could affect children's behavior during testing. The amount of
experience that children in any program had with actual test-taking is probably
trivial in comparison to the amount of experience some children got in doing
workbook pages and similar sorts of paper-and-pencil activities. And the nature
of these activities might have varied from ones calling for constructed
responses, quite unlike those on a multiple-choice test, to ones that amounted
virtually to a daily round of multiple-choice test-taking. Programs vary not
only in the amount of evaluation to which children are subjected but also in the
manner of evaluationp;be it covert, which might have little effect on the
children, or face-to-face and oral, or carried out through group testing.
Finally, given that testing conditions in the Follow Through evaluation were not
ideal, it is probably relevant how well children in the various programs learned
to cheat effectivelyp;that is, to copy from the right neighbor.
Some
or most of these variables could be extracted from available information, and it
would be then possible to carry out analyses showing the extent to which they
account for test scores and for the score differences between models. Only
through such a multivariate empirical investigation could we hope to judge how
seriously to take suggestions that the score differences among models were
artifactual. Until that time, insinuations about "teaching for the test" must be
regarded as mere prejudice.
What Do The Results Mean?
What we have tried to establish so far is that there are significant
achievement test differences between Follow Through models and that, so far as
we can tell at present, these test score differences reflect actual differences
in school learning. Beyond this point, conclusions are highly conjectural.
Although our main purpose in this paper has been simply to clarify the empirical
results of the Follow Through experiment, we shall venture some interpretive
comments, if for no other purpose than to forestall possible
misinterpretations.
The two high-scoring models according to our analysis
are Direct Instruction and Behavior Analysis; the two low-scoring are EDC Open
Education and Responsive Education. If there is some clear meaning to the Follow
Through results, it ought to emerge from a comparison of these two pairs of
models. On the one hand, distinctive characteristics of the first pair are easy
to name: sponsors of both the Direct Instruction and Behavior Analysis models
call their approaches "behavioral" and "structured" and both give a high
priority to the three R's. EDC and Responsive Education, on the other hand, are
avowedly "child-centered." Although most other Follow Through models could also
claim to be child-centered, these two are perhaps the most militantly so and
most opposed to what Direct Instruction and Behavior Analysis stand
for.
Thus we have, if we wish it, a battle of the philosophies, with the
child-centered philosophy coming out the loser on measured achievement, as it
has in a number of other experiments (Bennett, 1976; Stallings, 1975; Bell and
Switzer, 1973; Bell, Zipousky & Switzer, 1976). This is interesting if one
is keen on ideology, but it is not very instructive if one is interested in
improving as educational program. Philosophies don't teach kids. Events teach
kids, and it would be instructive to know what kinds of events make the
difference in scholastic achievement that we have observed.
The teaching
behavior studies of Brophy & Good (1974), Rosenshine (1976), and Stallings
& Kaskowitz (1974) are helpful on this point. Generally they contrast direct
with informal teaching styles, a contrast appropriate to the two kinds of models
we are comparing. Consistently it is the more direct methods, involving clear
specifications of objectives, clear explanations, clear corrections of wrong
responses, and a great deal of "time on task," that are associated with superior
achievement test performance. The effects tend to be strongest with
disadvantaged children.
These findings from teacher observation studies
are sufficiently strong and consistent that we may reasonable ask what if
anything Follow Through results add to them. They add one very important
element, the element of experimental change. The teacher observation studies are
correlational. They show that teachers who do x get better achievement results
than those who do y. The implication is that if the latter teachers switched
from doing y to doing x, they would get better results, too; but correlational
studies can't demonstrate that. Perhaps teachers whose natural inclination is to
do y will get worse results if they try to do x. Or maybe teachers who do y
can't or worse won't do x. Or maybe x and y don't even matter; they only serve
as markers for unobserved factors that really make the difference.
The
Follow Through experiment serves, albeit imperfectly, to resolve these
uncertainties. Substantial resources were lavished on seeing to it that teachers
didn't just happen to use direct or informal methods according to their
inclinations by rather that they used them according to the intent of the model
sponsors. The experimental control was imperfect because communities could
choose what Follow Through model to adopt, and in some cases, we understand,
teachers could volunteer to participate. Nevertheless, it seems safe to assume
that there was some sponsor effect on teacher behavior in all instances, so that
some teachers who would naturally do x were induced to do y and vise-versa.
Thus, with tentativeness, we can infer from Follow Through results that getting
teachers of disadvantaged children to use more direct instructional methods as
opposed to more informal ones will lead to superior achievement in commonly
tested basic skills.
Before concluding, however, that what accounts for
the superior achievement test scores of Direct Instruction and Behavior Analysis
sites is their use of direct teaching methods, we should consider a more
profound way in which these two models are distinguished from the others. These
models are distinctive not only at the level of immediately observable teacher
behavior but also at a higher level which may be called the systemic. One may
observe a lesson in which the teacher manifests all the usual signs of direct
teaching- lively manner, clear focus on instructional objectives, frequent
eliciting of response from students, etc. One may return weeks later to find the
same teacher with the same class manifesting the same direct teaching
behavior-and still teaching the same lesson! The fault here is at the systemic
level: the teacher is carrying out sorts of activities that should result in
learning but is failing to organize and regulate them in such a way as to
converge on the intended objectives.
More effective teachers-and this
includes the great majority- function according to a convergent system. Consider
a bumbling Mr. Chips introducing his pupils to multiplication by a two-digit
multiplier. He demonstrates the procedure at the chalkboard and then discovers
that most of the students cannot follow the procedure because they have
forgotten or never learned their multiplication facts. So he backs up and
reviews these facts, then demonstrates the algorithm again and assigns some
practice problems. Performance is miserable, so he teaches the lesson again. By
this time some children get it, and they teach others. With a bit of help, most
of the class catches on. Mr. Chips then gives special tutoring, perhaps with use
of supplementary concrete materials, to the handful of students who haven't yet
got it. Finally everyone has learned the multiplication algorithm except for the
slowest pupils in the class-who, as a matter of fact, haven't yet learned to add
either.
Although none of the procedures used by Mr. Chips are very
efficient, he applies them in a convergent way so that eventually almost all the
children reach the instructional objective. Some of his procedures may not have
a convergent effect at all. For instance, he may assign practice worksheets to
pupils who haven't yet grasped the algorithm, and the result is that they merely
practice their mistakes (a divergent activity). But the overall effect is
convergent. Given more efficient activities, convergence on the instructional
goal might be more rapid and it might include the pupils who fail at the hands
of Mr. Chips. But the difference in effectiveness, averaged over all pupils,
would probably not be great. This convergent property of teaching no doubt
contributes, as Stephens (1967) has suggested, to the scarcity of significant
differences between teaching methods. Unless severely constrained, most teachers
will see to it that, one way or another, their students reach certain goals by
the end of the term.
We suggest that teaching performance of the kind
just described be taken as baseline and that innovative educational practices,
such as those promoted by the Follow Through sponsors, be judged in relation to
that baseline. What would happen to the teaching of our Mr. Chips if he came
under the supervision of a Follow Through sponsor? It seems fairly clear that
his system for getting students to reach certain goals by the end of the term
would be enhanced if he took guidance from a Direct Instruction or Behavior
Analysis sponsor but that it might well be disrupted by guidance from one of the
more child-centered sponsors.
What Direct Instruction and Behavior
Analysis provide are more fully developed instructional systems than teachers
normally employ. They provide more systematic ways of determining whether
children have the prerequisite skills before a new step in learning is
undertaken, more precise ways of monitoring what each child is learning or
failing to learn, and more sophisticated instructional moves for dealing with
children's learning needs. Open Education and Responsive Education, on the other
hand, because of their avowed opposition to making normative comparisons of
students or thinking in terms of deficits, will tend to discourage those
activities whereby teachers normally discover when children are not adequately
prepared for a new step in learning or when a child has mislearned or failed to
learn something. Also, because of their preference for indirect learning
activities, these models will tend to make teaching less sharply focused on
achieving specific earnings and remedying specific lacks.
Of course,
child-centered educators will wish to describe the matter differently, arguing
that they do have a well-developed system for promoting learning; but it is a
different kind of system pursuing different kinds of goals from those pursued by
the direct instructional approaches. They will point out that child-centered
teachers devote a great deal of effort to identifying individual pupils'
learning needs and to providing learning experiences to meet these needs; it is
just that their efforts are more informal and intuitive, less programmed.
Child-centered education, they will argue, is different, not
inferior.
One is inclined automatically to assent to this
live-and-let-live assessment, which relegates the differences between
educational methods to the realm of personal values and ideology. But surely the
Follow Through experiment and any comparative evaluation will have been in vain
if we take this easy way out of the dilemma of educating disadvantaged
children.
This easy way of avoiding confrontation between the two
approaches can be opposed on both empirical and theoretical grounds.
Empirically, child-centered approaches have been unable to demonstrate any
off-setting advantages to compensate for their poor showing in teaching the
three R's. House et al (1978a) have argued that the selection of measures used
in the Follow Through evaluation did not give child-centered approaches adequate
opportunity to demonstrate their effects. This may be true to a degree, but it
is certainly not true that child-centered approaches had no opportunity to
demonstrate effects relevant to their purposes. One had better not be a
perfectionist when it comes to educational evaluation. No measure is perfectly
correlated to one's objectives. The most one can hope for is a substantial
correlation between obtained scores on the actual measures and true scores on
the ideally appropriate measures that one wishes existed but do not.
When
child-centered educators purport to increase the self-esteem of disadvantaged
children and yet fail to show evidence of this on the Coopersmith Self-Concept
Inventory, we may ask what real and substantial changes in self-esteem would one
expect to occur that would not be reflected in changes on the Coopersmith?
Similarly for reasoning and problem-solving. If no evidence of effect shows on a
test of non-verbal reasoning, or a reading comprehension test loaded with
inferential questions, or on a mathematical problem solving test, we must ask
why not? What kinds of real, fundamental improvements in logical reasoning
abilities would fail to be reflected in any of these tests?
If these
remarks are harsh, it is only because we believe that the question of how best
to educate disadvantaged children is sufficiently serious that a policy of
live-and-let-live needs to be replaced by a policy of put-up-or-shut-up.
Certainly the cause of educational betterment is not advanced by continual
appeal to nonexistent measures having zero or negative correlations with
existing instruments purporting to measure the same thing. Among the numerous
faults that we have found with the House committee's report, their use of this
appeal is the only one that deserves the label of sophistry.
Critique of the Child-centered Approach
What follows is an attempt at a constructive assessment of the child-centered
approach as embodied in the Open Education and Responsive Education models. By
constructive we mean that we take seriously the goals of these models and that
our interest is in realizing the goals rather than in scrapping them in favor of
others. These remarks are by way of preface to the following observation:
child-centered approaches have evolved sophisticated ways of managing informal
educational activities but they have remained at a primitive level in the design
of means to achieve learning objectives.
We are here distinguishing
between two levels at which a system of teaching may be examined. At the
management level, an open classroom and a classroom running according to a token
economy, for example, are radically different, and while there is much to
dispute in comparing them, it is at least clear that both represent highly
evolved systems. When we consider the instructional design level, however, the
difference is more one-sided. Child-centered approaches rely almost exclusively
on a form of instruction that instructionally-oriented approaches use only when
nothing better can be found.
This primitive form of instruction may be
called relevant activity. Relevant activity is what teachers must resort to when
there is no available way to teach children how to do something, no set of
learning activities that clearly converge on an objective. This is the case, for
instance, with reading comprehension. Although there are some promising
beginnings, there is as yet no adequate "how-to-do-it" scheme for reading
comprehension. Accordingly, the best that can be done is to engage students in
activities relevant to reading comprehension-for instance, reading selections
and answering questions about the selections. Such activities are relevant in
that they entail reading comprehension, but they cannot be said to teach reading
comprehension.
For many other areas of instruction, however, more
sophisticated means have been developed. There are, for instance, ways of
teaching children how to decode in reading and how to handle equalities and
inequalities in arithmetic (Engelmann, Ref. Note 2). The instructional
approaches used in Direct Instruction and Behavior Analysis reflect years of
analysis and experimentation devoted to finding ways of going beyond relevant
activity to forms of instruction that get more directly at cognitive skills and
strategies. This effort has been successful in some areas, not so successful in
others, but the effort goes on. Meanwhile, child-centered approaches have tended
to fixate on the primitive relevant activities form of instruction for all their
instructional objectives.
The contrast of sophistication in management
and naiveté in instruction is visible in any well-run open classroom. The
behavior that meets the eye is instantly appealing-children quietly absorbed in
planning, studying, experimenting, making things-and one has to marvel at the
skill and planning that have achieved such a blend of freedom and order. But
look at the learning activities themselves and one sees a hodge-podge of the
promising and the pointless, of the excessively repetitious and the excessively
varied, of tasks that require more thinking than the children are capable of and
tasks that have been cleverly designed to require no mental effort at all (like
exercise sheets in which all the problems on the page have the same answer). The
scatteredness is often appalling. There is a little bit of phonics here and a
little bit of phonics there, but never a sufficiently coherent sequence to
enable a kid to learn bow to use this valuable tool. Materials have been chosen
for sensorial appeal or suitability to the system of management. There is a
predilection for cute ideas. The conceptual analysis of learning problems tends
to be vague and irrelevant, big on name-dropping and low on
incisiveness.
There does not appear to be any intrinsic reason why
child-centered educators should have to remain committed to primitive
instructional approaches. So far, child-centered educators have been able to
gain reassurance from the fact that for the objectives they emphasize-objectives
in comprehension, thinking, and feeling-their approaches are no more ineffective
than anyone else's. But even this defense may be crumbling. Instructional
designers, having achieved what appears to be substantial success in improving
the teaching of decoding in reading, basic mathematical concepts and operations,
spelling, and written English syntax, are now turning more of their attention to
the kinds of goals emphasized by child-centered educators. Unless thinkers and
experimenters committed to child-centered education become more sophisticated
about instruction and start devoting more attention to designing learning
activities that actually converge on objectives, they are in danger of becoming
completely discredited. That would be too bad. Child-centered educators have
evolved a style of school life that has much in its favor. Until they develop an
effective pedagogy to go with it, however, it does not appear to be an
acceptable way of teaching disadvantaged children.
*Graphs and tables in
this article could not be reproduced clearly in electronic
format.
Notes:
1. Reduced analyses were performed, dropping TEEM and
Cognitive Curriculum from the analysis. These were the two most unstable models
in the sense of shifting most in relative performance depending on the choice of
covariates. Moreover, Cognitive Curriculum had deviant relations between
criteria and covariates, showing for instance negative relationships between
achievement and SES. The only effect of removing these models, however, was to
increase the number of significant differences between the two top scoring
models and the other models.
2. Examined closely, the House et al
statement is a bit slippery. Since the MAT is a norm-referenced, (not a
criterion-referenced) test, it is of course "reckless" to infer any particular
attainments at all from test scores. All we know is how a person or group
performs in comparison to others. If, for example, the criterion for "ability to
write a story" is set high enough, it would be reckless to suppose that any
third-grader had attained it.
3. The obvious targets for the charge of
emphasizing rote learning are Direct Instruction and Behavior Analysis. However,
the Direct Instruction sponsors explicitly reject rote memorization (Bock,
Stebbins, & Proper, 1977, p. 65) and the Behavior Analysis model description
makes no mention of it. House, Glass, McLean, and Walker seem to have fallen
into the common fallacy here of equating direct instruction with rote learning.
If they are like most university professors, they probably rely extensively on
direct instruction themselves and yet would be offended by the suggestion that
this means they teach by rote.
Reference Notes:
1. Becker, W.C.,
& Carnine, D.W. Direct Instruction-A behavior-based model for comprehensive
educational intervention with the disadvantaged. Paper presented at the VIII
Symposium on Behavior Modification, Caracas, Venezuela, February, 1978. Division
of Teacher Education, University of Oregon, Eugene, Oregon.
2. Engelmann,
S. Direct Instruction. Seminar presentation. AERA, Toronto, March, 1978.
References
Bell, A.E., & Switzer, F. (1973). Factors related to pre-school
prediction of academic achievement: Beginning reading in open area vs.
traditional classroom systems. Manitoba Journal of Education, 8,
22-27.
Bell, A.E., Zipuvsky, M.A., and Switzer, F. (1977). Informal or
open-area education in relation to achievement and personality. British Journal
of Educational Psychology, 46. 235-243.
Bennett, N. (1976). Teaching
styles and pupil progress. Cambridge, Mass.: Harvard University
Press.
Brophy, J.E., & Good, T.L. (1974). Teacher-student
relationships: Causes and consequences. New York: Hold, Rinehart &
Winston.
Cronbach, L.J. (1960). Essentials of psychological testing. (2nd
ed.). New York: Harper & Brothers.
House, E.R., Glass, G.V., McLean,
L.F., and Walker, D.F. (1978a). No Simple Answer: Critique of the "Follow
Through" evaluation. Harvard Educational Review, 28(2), 128-160.
House,
E.R., Glass, G.V., McLean, L.F., and Walker, D.F. (1978b). Critiquing a Follow
Through evaluation. Phi Delta Kappan, 59(7), 473-474.
Rosenshine, B.
Classroom Instruction. (1976). In Seventy-fith Yearbook of the National Society
for the Study of Education (Part 1). Chicago: University of Chicago
Press.
St. Pierre, R.G., Anderson, R.B., Proper, E.C., and Stebbins, L.B.
(1978). That Follow Through evaluation. Phi Delta Kappan, 59(10),
729.
Stallings, J.A., & Kaskowitz, D.H. (1974). Follow Through
classroom observation evaluationp;1972-1973. Menlo Park, Cal.: Stanford
Research Institute.
Stallings, J. (1975). Implementation and child
effects of teaching practices in Follow Through classrooms. Monographs of the
Society for Research in Child Development, 40(7-8, Serial No.
163).
Stebbins, L.B., St. Pierre, R.G., Proper, E.C., Anderson, R.B., and
Cerva, T.R. (1977). A planned variation model. Vol. IV-A Effects of Follow
Through models. U.S. Office of Education.
Stephens, J. (1967). The
process of schooling. New York: Holt, Rinehart & Winston.
Back to
Table of Contents